Big Data – You Can’t Analyze What You Don’t Have
- gvalyou

- Apr 27, 2016
- 3 min read
Updated: Mar 16, 2019
In the information technology world, we have all heard the hype around Big Data, Data Lakes, Structured Data, Unstructured Data, NoSQL, Hadoop, Spark, Hive, Ranger, Falcon, HBase, Cassandra, In Memory Processing, and many other related terms. These terms may mean something to a technical team, but to the rest of an organization Big Data is defined by what it can do and what is needed to do it.

We live in a world that is producing a large and ever increasing amount of data. Data from many disparate sources that is often very unrelated, unorganized and noisy. Data who's value we often don’t know at the time of its creation. In most organizations, all but the most essential data is often discarded as storage can require a significant investment in terms of both actual hardware and resources to support and maintain. But what if the discarded information at some point becomes useful or important? Like video of the grandparent that you wish you had so you could hear their voice and see their smile. At the time you did not know how much you would wish you would have stored video of your grandparent and what the true value and importance would be years later.
In Healthcare, data from traditional and many new and non-traditional sources is beginning to be used to identify and provide actionable insight into specific diseases and medical conditions, allowing healthcare providers and insurance companies the opportunity to intervene or educate much more accurately and earlier. Maybe even before a disease becomes a disease!
The following passage from a recently published article on the National Institutes of Health (NIH) website, highlights the importance of having the right data available for analysis, “in a recent study in Science Translational Medicine [1], NIH-funded researchers demonstrated the tremendous potential of using EHRs, combined with genome-wide analysis, to learn more about a common, chronic disease—type 2 diabetes. Sifting through the EHR and genomic data of more than 11,000 volunteers, the researchers uncovered what appear to be three distinct subtypes of type 2 diabetes. Not only does this work have implications for efforts to reduce this leading cause of death and disability, it provides a sneak peek at the kind of discoveries that will be made possible by the new Precision Medicine Initiative’s national research cohort, which will enroll 1 million or more volunteers who agree to share their EHRs and genomic information.” (1)
Per the article, the data driven study identified three new distinct subtypes of complication classifications. This information may help medical practitioners, insurance companies, wellness organizations and maybe patients themselves be aware and proactively manage the potential complications of type 2 diabetes with a more targeted and customized approach, but none of it can occur without data available.
The following infographic from IBM (2) highlights this treasure trove of health information beyond traditional diagnosis and treatment data and the need for strategies and solutions to store and retain this information.
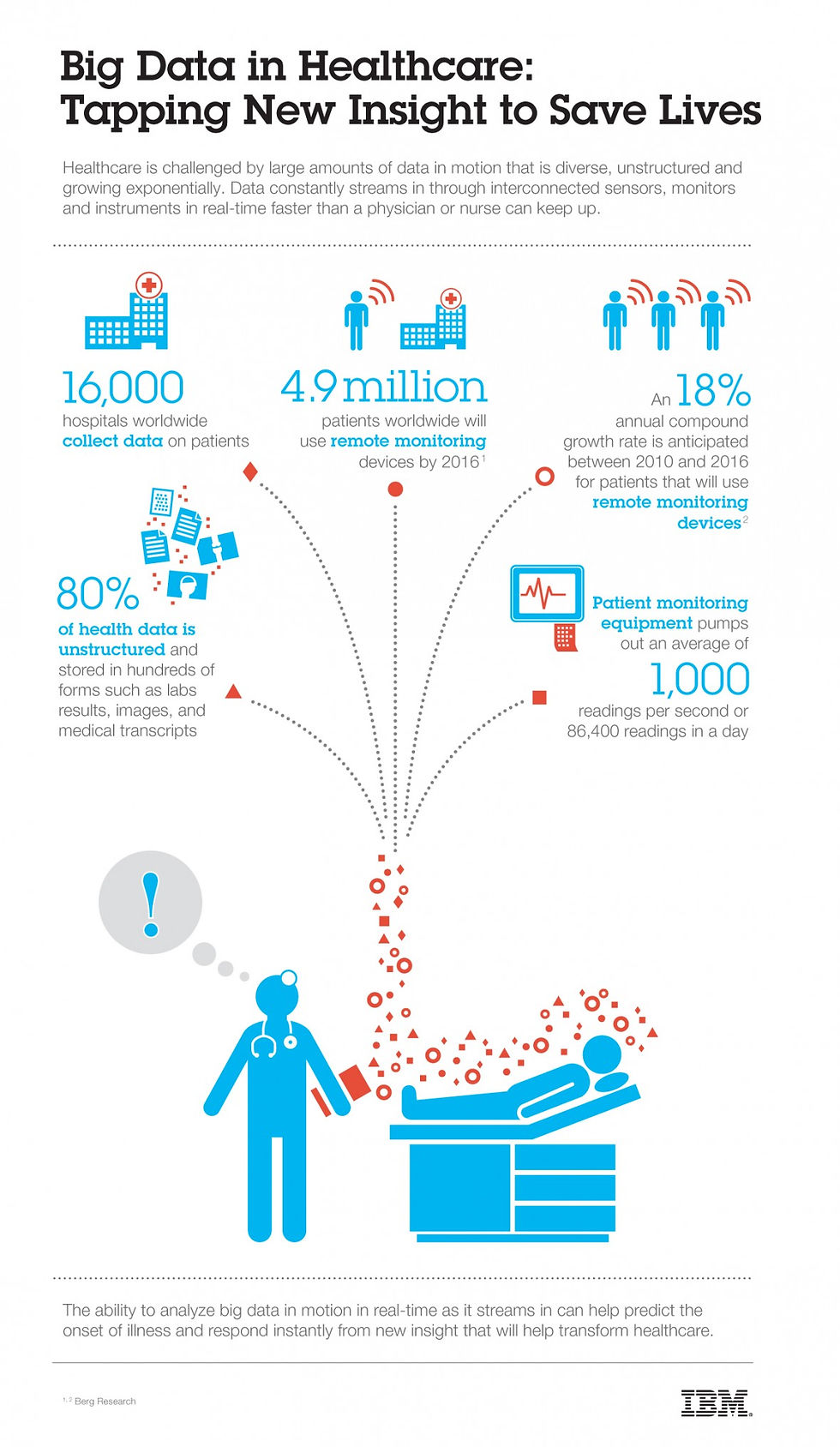
We are early in the innovation cycle that leverages many new types of data to positively impact healthcare. Big Data has helped us start to see glimmers of that promise as we develop new and more efficient tools and processes to store, secure, process and analyze more and more healthcare related data. Data retention strategies and processes are an important part of any successful long term Big Data solution, because you can’t analyze what you don’t have!
References and Citations:
NIH Website, “Big Data Study Reveals Possible Subtypes of Type 2 Diabetes”, https://directorsblog.nih.gov/2015/11/10/big-data-reveals-possible-subtypes-of-type-2-diabetes/, Dr. Francis Collins, November 10, 2015
IBM Big Data Hub Website, “Big Data in Healthcare: Tapping New Insight to Save Lives”, http://www.ibmbigdatahub.com/infographic/big-data-healthcare-tapping-new-insight-save-lives, 4/23/2016
Disclaimer, Copyright and Trademark Statement
This article is provided for informational and educational purposes. It makes no warranties as to the claims, accuracy or fitness of information provided, referenced or cited. Use of the information, instructions and any examples contained in this work is at your own risk. There should be no implied endorsement of this article by any person or organization referenced.
All trademarks, company, product and services names, images, descriptions, or public website content are property of their respective owner as source referenced. It is your responsibility to ensure that your use thereof complies with such licenses and/or rights.


